Datenbereinigung: der große Überblick zur Sicherung von Datenqualität in Unternehmen
Was sind Datenbereinigung, Data Cleaning und Data Cleansing?
Datenbereinigung oder auf Englisch Data Cleaning , bezieht sich auf den Prozess der Änderung, Löschung oder Veränderung von Datensätzen. Das Ergebnis verbessert die Qualität der Informationen und macht sie wertvoll für alle Folgeprozesse datenbasierten Arbeitens.
Obwohl die Begriffe Data Cleaning und Data Cleansing oft synonym verwendet werden, gibt es feine Unterschiede zwischen den beiden:
- Data Cleaning bezieht sich in der Regel auf den Prozess der Identifizierung und Korrektur von Fehlern und Ungenauigkeiten in den Daten, wie z. B. Tippfehler oder inkonsistente Schreibweisen.
- Data Cleansing bezieht sich hingegen auf einen umfassenderen Prozess, der auch das Entfernen von Duplikaten, das Auffüllen fehlender Werte und die Transformation von Daten in ein standardisiertes Format umfasst.
Beispiel:
Beispiel 1: Es könnte ein Unternehmen feststellen, dass es in seiner Kundendatenbank mehrere Einträge für denselben Kunden gibt, weil der Name des Kunden in einigen Fällen mit einem Mittelnamen und in anderen Fällen ohne eingegeben wurde. Durch die Standardisierung der Art und Weise, wie Kundennamen eingegeben werden, kann das Unternehmen diese Duplikate identifizieren und zusammenführen, wodurch die Genauigkeit und Konsistenz seiner Daten verbessert werden.
Beispiel 2: Die Datenbereinigung kann auch dazu dienen, fehlende oder unvollständige Daten zu ergänzen. Wenn beispielsweise in einigen Datensätzen die Telefonnummer eines Kunden fehlt, könnte das Unternehmen einen Prozess einrichten, um diese fehlenden Daten auf der Grundlage anderer Informationen, wie der E-Mail-Adresse oder der Postanschrift des Kunden, zu ergänzen.
Insgesamt ist die Datenbereinigung, ob als Data Cleaning oder Data Cleansing bezeichnet, ein wichtiger Schritt zur Verbesserung der Datenqualität und zur Sicherstellung, dass Unternehmen auf der Grundlage ihrer Daten genaue und fundierte Entscheidungen treffen können.
Die Bedeutung der Datenbereinigung für Unternehmen
Die Datenbereinigung spielt eine entscheidende Rolle in der Datenverwaltung und -analyse. Sie ist ein Prozess, der darauf abzielt, Fehler, Ungenauigkeiten und Inkonsistenzen in Datensätzen zu identifizieren und zu korrigieren. Die Bedeutung der Datenbereinigung kann nicht genug betont werden, da sie direkt die Qualität der Daten und damit die Qualität der darauf basierenden Entscheidungen und Erkenntnisse beeinflusst.
Ein wichtiger Anwendungsbereich der Datenbereinigung ist die Datensatzverknüpfung, auch bekannt als Datenzusammenführung oder Datenintegration. Dies ist der Prozess, bei dem zwei oder mehr Datensätze, die Informationen über dieselbe Einheit enthalten, zusammengeführt werden. Die Qualität der Verknüpfungsergebnisse hängt stark von der Qualität der zugrunde liegenden Daten ab. Wenn die Daten Fehler, Duplikate oder Inkonsistenzen enthalten, kann dies zu falschen oder irreführenden Verknüpfungsergebnissen führen.
Durch die Bereinigung der Daten vor der Verknüpfung können Unternehmen die Qualität der Verknüpfungsergebnisse erheblich verbessern. Beispielsweise kann das Entfernen von Duplikaten dazu beitragen, dass jede Einheit in den verknüpften Daten nur einmal vertreten ist. Das Auffüllen fehlender Werte kann dazu beitragen, dass die verknüpften Daten vollständiger und repräsentativer sind. Und die Korrektur von Fehlern kann dazu beitragen, dass die verknüpften Daten genauer und zuverlässiger sind.
Chancen der Datenbereinigung
- Verbesserte Datenqualität: Durch die Bereinigung von Daten können Fehler, Duplikate und Inkonsistenzen entfernt werden, was zu genauen und zuverlässigeren Daten führt.
- Effizientere Datenverwaltung: Durch das Entfernen von Duplikaten und das Auffüllen fehlender Werte können Daten effizienter verwaltet und genutzt werden.
- Bessere Geschäftsentscheidungen: Mit sauberen, genauen und aktuellen Daten können Unternehmen fundiertere und effektivere Geschäftsentscheidungen treffen.
- Einhaltung von Vorschriften: Die Datenbereinigung kann dazu beitragen, die Einhaltung von Datenschutz- und anderen Vorschriften zu gewährleisten, indem sie sicherstellt, dass die Daten korrekt und vollständig sind.
Trotz der zahlreichen Vorteile der Datenbereinigung ist es wichtig zu beachten, dass sie auch Risiken birgt. Wenn sie nicht sorgfältig durchgeführt wird, kann die Datenbereinigung zu Datenverlust führen, insbesondere wenn wichtige Informationen fälschlicherweise als Fehler oder Duplikate identifiziert und entfernt werden. Darüber hinaus kann die Datenbereinigung, wenn sie ohne angemessene Datenschutzmaßnahmen durchgeführt wird, zu Datenschutzverletzungen führen.
Daher ist es entscheidend, dass Unternehmen bei der Durchführung der Datenbereinigung sorgfältige und durchdachte Strategien anwenden, um diese Risiken zu minimieren.
Herausforderungen/Risiken
- Datenverlust: Bei der Datenbereinigung besteht das Risiko, dass wichtige Daten verloren gehen oder beschädigt werden, insbesondere wenn die Bereinigung nicht sorgfältig durchgeführt wird.
- Zeitaufwand: Die Datenbereinigung kann ein zeitaufwändiger Prozess sein, insbesondere bei großen Datensätzen.
- Komplexität: Die Datenbereinigung kann komplex sein, insbesondere wenn die Daten aus verschiedenen Quellen stammen und in verschiedenen Formaten vorliegen.
- Datenschutz und Compliance: Bei der Datenbereinigung müssen oft Datenschutz- und Compliance-Anforderungen berücksichtigt werden, was zusätzliche Herausforderungen darstellen kann.
Typische Probleme bei der Datenbereinigung
Die Datenbereinigung ist ein unverzichtbarer Prozess zur Verbesserung der Datenqualität, kann aber auch eine Reihe von Herausforderungen mit sich bringen. Hier sind einige der häufigsten Probleme, die bei der Datenbereinigung auftreten können:
- Identifizierung von Duplikaten: Die Identifizierung von Duplikaten kann eine Herausforderung sein, insbesondere in großen Datensätzen. Es kann schwierig sein zu bestimmen, welche Datensätze tatsächlich Duplikate sind und welche nur ähnlich sind.
- Umgang mit fehlenden Daten: Fehlende Daten können ein großes Problem darstellen. Es kann schwierig sein zu entscheiden, wie man mit fehlenden Daten umgeht - sollte man sie ignorieren, sie mit Durchschnittswerten füllen oder die fehlenden Daten auf andere Weise schätzen?
- Inkonsistente Daten: Daten können auf verschiedene Weisen inkonsistent sein, z.B. können Datumswerte in verschiedenen Formaten vorliegen oder Textdaten können in verschiedenen Sprachen sein. Diese Inkonsistenzen zu identifizieren und zu beheben, kann eine Herausforderung sein.
- Veraltete Daten: Daten können veralten, und es kann schwierig sein zu bestimmen, welche Daten veraltet sind und aktualisiert oder entfernt werden sollten.
- Falsche Daten: Manchmal können Daten einfach falsch sein. Die Identifizierung und Korrektur falscher Daten kann eine große Herausforderung sein.
- Skalierung der Datenbereinigung: Die Datenbereinigung kann eine zeitaufwändige Aufgabe sein, und es kann eine Herausforderung sein, die Datenbereinigung auf große Datensätze zu skalieren.
- Datenschutz und Compliance: Bei der Datenbereinigung müssen oft Datenschutz- und Compliance-Anforderungen berücksichtigt werden. Dies kann eine zusätzliche Herausforderung darstellen.
- Qualitätssicherung nach der Bereinigung: Nach der Datenbereinigung ist es wichtig, die Qualität der bereinigten Daten zu überprüfen. Dies kann eine Herausforderung sein, insbesondere wenn die Datenbereinigung automatisiert wurde.
- Auswahl der richtigen Tools und Techniken: Es gibt viele verschiedene Tools und Techniken für die Datenbereinigung, und die Auswahl der richtigen kann eine Herausforderung sein.
- Ausbildung und Kompetenzentwicklung: Die Datenbereinigung erfordert spezielle Fähigkeiten und Kenntnisse. Die Ausbildung von Mitarbeitern in diesen Fähigkeiten und Kenntnissen kann eine Herausforderung sein.
Probleme bei der Datenbereinigung mit Excel
Die Datenbereinigung mit Excel kann eine zeitaufwändige und fehleranfällige Aufgabe sein. Es gibt viele Probleme, die bei der Datenbereinigung mit Excel auftreten können, wie z.B. fehlende oder falsche Daten, Duplikate, Formatierungsprobleme und unstrukturierte Daten. Diese Probleme können dazu führen, dass die Ergebnisse der Analyse ungenau oder unvollständig sind.
Beispielsweise kann das Entfernen von Duplikaten in Excel eine mühsame Aufgabe sein, insbesondere wenn die Datenmenge groß ist. Excel bietet zwar Funktionen zum Entfernen von Duplikaten, aber diese können bei großen Datenmengen langsam und ineffizient sein. Darüber hinaus kann das manuelle Entfernen von Duplikaten zu menschlichen Fehlern führen, die die Datenqualität weiter beeinträchtigen.
Ein weiteres häufiges Problem bei der Datenbereinigung mit Excel ist der Umgang mit fehlenden oder falschen Daten. Excel bietet zwar Funktionen zum Auffüllen fehlender Werte und zur Korrektur falscher Daten, aber diese erfordern oft manuelle Eingriffe und können bei großen Datenmengen zeitaufwändig sein.
AnalyticsGate als Lösung
Im Gegensatz zu Excel, das ursprünglich nicht für die Datenbereinigung konzipiert wurde, bietet AnalyticsGate eine automatisierte Fehlererkennung und kann somit als effizientes Tool im gesamten Prozess der Datenbereinigung eingesetzt werden. AnalyticsGate kann z. B. Duplikate automatisch erkennen. Darüber hinaus bietet AnalyticsGate eine benutzerfreundliche Oberfläche, die es dem Benutzer ermöglicht, die Daten schnell und einfach manuell zu bereinigen.
AnalyticsGate und Datenbereinigung: Funktionen und Möglichkeiten
Der Datenbereinigungsprozess kann zeitaufwändig und fehleranfällig sein. Normalerweise müssen Fehler oder Ungenauigkeiten in Datensätzen aufwendig identifiziert werden. Dank der automatisierten Fehlererkennung von AnalyticsGate kann diese Aufgabe nun verkürzt werden. Dies spart nicht nur Zeit, sondern reduziert auch menschliche Fehler.
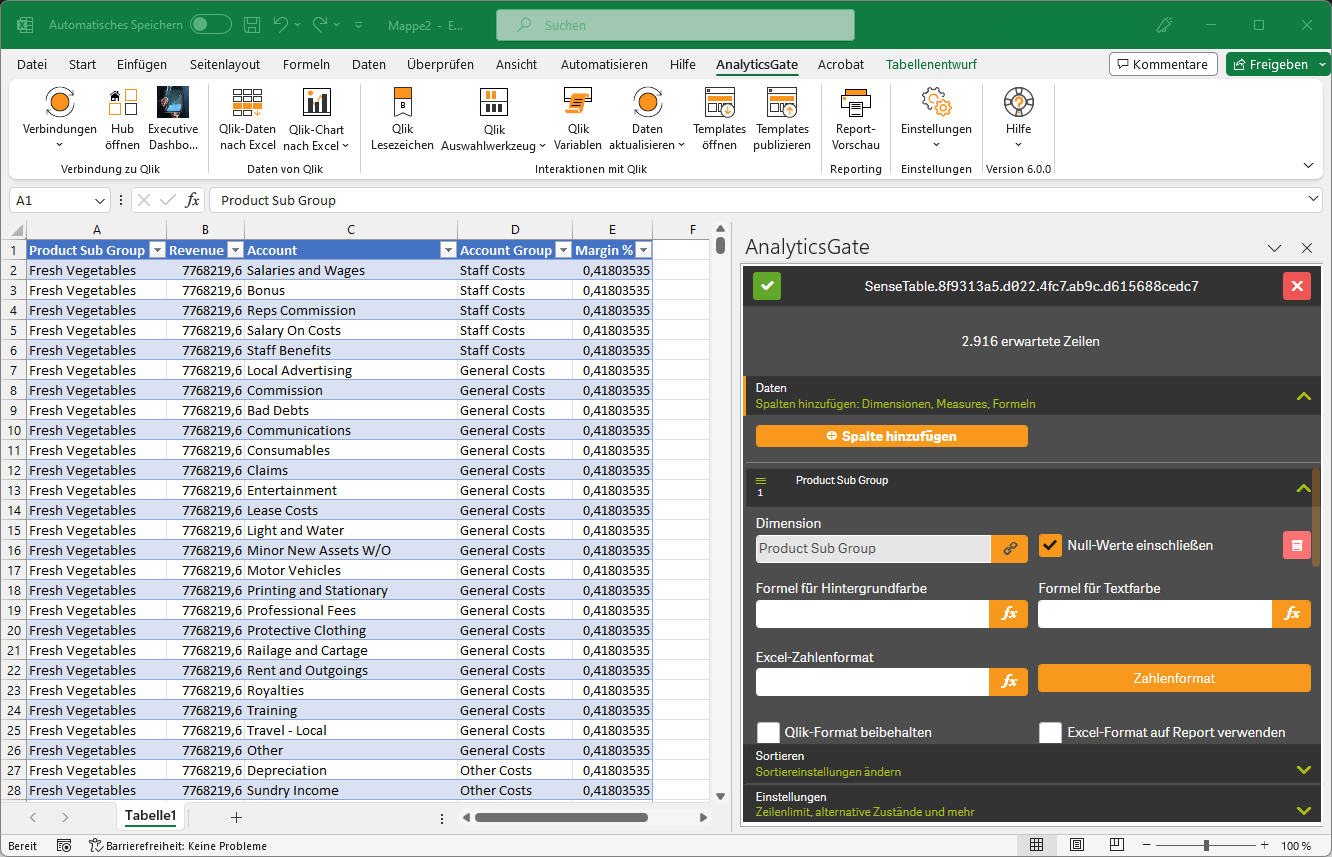
Obwohl AnalyticsGate nicht speziell als Datenbereinigungstool entwickelt wurde, bietet es Funktionen, die bei der Datenbereinigung nützlich sein können.
Datenimport: AnalyticsGate ermöglicht es Benutzern, Daten aus Qlik Sense in eine Excel-Tabelle zu importieren. Diese Tabellen reagieren auf die Anwendung von Filtern und Lesezeichen und können von Excel verwendet werden, um abgeleitete Berechnungen, Diagramme und Pivot-Tabellen zu erstellen.
Dynamische Aktualisierung: Einmal importierte Daten und Visualisierungen in Excel sind nicht statisch. Sie können dynamisch aktualisiert werden, wenn sich die zugrunde liegenden Daten in Qlik Sense ändern oder wenn Benutzer verschiedene Filter oder Lesezeichen anwenden.
Formelbasiertes Reporting: Mit dem AnalyticsGate Add-In werden zusätzliche Formeln Teil der Excel-Formelbibliothek. Diese Formeln, im Wesentlichen KPI-Berechnungen, werden auf einer Zelle-für-Zelle-Basis angewendet und nutzen dabei die integrierte Qlik- und Excel-Formelsyntax.
Berichterstellung und -verteilung: Mit AnalyticsGate können Benutzer Berichte erstellen, die auf Qlik Sense-Daten basieren, und diese Berichte dann an andere verteilen. Dies kann entweder auf Anfrage geschehen, oder es können automatisierte Berichtsverteilungen eingerichtet werden.
Integration mit Qlik Sense: AnalyticsGate ermöglicht eine nahtlose Integration mit Qlik Sense, einschließlich der Möglichkeit, Qlik Sense-Filter und -Lesezeichen in Excel zu verwenden, Qlik Sense-Variablen in Excel-Formeln zu verwenden und vieles mehr.
Beispiel: Bereinigung von Kundendaten in einem E-Commerce-Unternehmen
Ausgangslage
Ein E-Commerce-Unternehmen hat in den letzten Jahren ein exponentielles Wachstum erlebt. Mit der Erweiterung ihres Kundenstamms und der Einführung neuer Produkte stiegen jedoch auch die Datenmengen, die das Unternehmen verwalten musste.
Dies führte zu einer Reihe von Datenqualitätsproblemen, darunter Duplikate von Kundeneinträgen, inkonsistente Adressformate und veraltete Kontaktinformationen. Diese Probleme beeinträchtigten die Effizienz der Marketingkampagnen und führten zu einer suboptimalen Kundenerfahrung.
Problemspezifizierung
Ein spezifisches Problem, das die Firma hatte, war die Inkonsistenz in der Art und Weise, wie Kundennamen in ihrer Datenbank erfasst wurden. Einige Kunden hatten ihren vollen Namen eingegeben, während andere nur ihren Vornamen verwendet hatten. In einigen Fällen wurden die Namen in Großbuchstaben geschrieben, in anderen in Kleinbuchstaben. Diese Inkonsistenzen führten dazu, dass das Unternehmen Schwierigkeiten hatte, genaue Kundenprofile zu erstellen und effektive personalisierte Marketingkampagnen durchzuführen.
Lösungsansatz
Um dieses Problem zu lösen, entschied sich die Firma für die Verwendung von AnalyticsGate zur Datenbereinigung. Mit AnalyticsGate konnte das Unternehmen eine Regel erstellen, die alle Kundennamen in ein einheitliches Format umwandelte - den ersten Buchstaben groß und den Rest klein. Darüber hinaus konnte AnalyticsGate Duplikate identifizieren, indem es nach Kundennamen und E-Mail-Adressen suchte, die in mehr als einem Eintrag vorhanden waren. Diese Duplikate wurden dann zusammengeführt, wobei die aktuellsten und vollständigsten Informationen beibehalten wurden.
Darüber hinaus konnte die Firma mit AnalyticsGate auch veraltete Kontaktinformationen aktualisieren. Das Unternehmen konnte eine Regel erstellen, die automatisch nach Kunden suchte, die seit mehr als einem Jahr keine Bestellung mehr aufgegeben hatten. Diese Kunden wurden dann als inaktiv markiert und aus den aktiven Marketingkampagnen entfernt.
Ergebnis
Durch die Automatisierung der Fehlererkennung mit AnalyticsGate konnte die Firma seine Datenqualität erheblich verbessern. Dies führte zu effektiveren Marketingkampagnen, da das Unternehmen nun genaue und konsistente Kundenprofile hatte, auf deren Grundlage es personalisierte Marketingbotschaften erstellen konnte. Darüber hinaus verbesserte sich die Kundenerfahrung, da die Kunden nun relevantere und zielgerichtete Kommunikation von einer Firma erhielten.
Persönliches Fazit des Autors:
„In der heutigen datengetriebenen Geschäftswelt ist die Datenqualität von entscheidender Bedeutung. Eine der wichtigsten Methoden zur Verbesserung der Datenqualität ist die Datenbereinigung. Obwohl es ein unverzichtbarer Prozess ist, stehen Unternehmen oft vor einer Reihe von Herausforderungen und Problemen bei der Durchführung der Datenbereinigung.
Die Datenbereinigung spielt eine entscheidende Rolle in der Datenverwaltung und -analyse. Sie ist ein Prozess, der darauf abzielt, Fehler, Ungenauigkeiten und Inkonsistenzen in Datensätzen zu identifizieren und zu korrigieren. Die Qualität der Verknüpfungsergebnisse hängt stark von der Qualität der zugrunde liegenden Daten ab. Wenn die Daten Fehler, Duplikate oder Inkonsistenzen enthalten, kann dies zu falschen oder irreführenden Verknüpfungsergebnissen führen.
Durch die Automatisierung der Fehlererkennung in Datensätzen können Unternehmen ihre Datenqualität erheblich verbessern. Dies führt zu effektiveren Geschäftsentscheidungen, da Unternehmen nun genaue und konsistente Daten haben, auf deren Grundlage sie Entscheidungen treffen können. Darüber hinaus verbessert sich die Kundenerfahrung, da Kunden nun relevantere und zielgerichtete Kommunikation von Unternehmen erhalten.
Zusammenfassend lässt sich sagen, dass die Datenbereinigung und Tools wie AnalyticsGate Unternehmen dabei helfen können, ihre Datenqualität zu verbessern und bessere Geschäftsentscheidungen zu treffen. Ich empfehle, dass Unternehmen Schulungen für Mitarbeiter zur Verbesserung der Datenqualität durchführen und Qualitätskontrollprozesse für Daten einführen.“